
Website founded by
Milan Velimirović
in 2006
17:50 UTC


| |
MatPlus.Net  Forum Internet and Computing PGN pseudo standard Forum Internet and Computing PGN pseudo standard |
| |
|
|
|
|
You can only view this page!
| | | (1) Posted by Hauke Reddmann [Monday, Oct 21, 2019 22:30] | PGN pseudo standard
It's not very glorious to save chess problems as PGN, I know.
Especially with annotations.
Is there a de facto standard to do it if one does so?
| | | (2) Posted by Vitaly Medintsev [Tuesday, Oct 22, 2019 08:57] |
Olive-GUI can save chess problems as pdf - https://github.com/dturevski/olive-gui/releases
Main menu -> File -> Export -> Collection to PDF
| | | (3) Posted by Hauke Reddmann [Tuesday, Oct 22, 2019 21:32] |
PDF sounds even worse (unless you can load it again).
I was dreaming for a cross-platform (say at least
Popeye-derived, WinChloe and Alybadix) standard...
PGN was suggesting itself, but if we manage to lock
Thomas Maeder, Christian Poisson and Ilkka Blom into
a room with water and bread until they agreed on an
optional text-based format... :-)
| | | (4) Posted by Vitaly Medintsev [Wednesday, Oct 23, 2019 08:44] |
PDF is the standard for many digital libraries.
So why is it not suitable for storing chess problems?
Probably I didn't understand the purpose.
| | | (5) Posted by Frank Richter [Wednesday, Oct 23, 2019 11:55] |
It's quite difficult to load a PDF into the solving programs, mentioned above by Hauke. I assume, that is his main purpose - to have a storage notation, that is supported by the most solving/database solutions.
| | | (6) Posted by Dmitri Turevski [Wednesday, Oct 23, 2019 13:21] |
At the Rhodes meeting in the 2007 the standard format for the representation of chess problems was accepted:
https://www.wfcc.ch/1999-2012/dec07/
The project homepage:
http://problem-xml.sourceforge.net/
The mailing group (spammed, you have scroll down for actual talks):
https://groups.google.com/forum/#!forum/chess-problem-xml
The project looks abandoned now, is it?
| | | (7) Posted by Hauke Reddmann [Thursday, Oct 24, 2019 10:50] |
The page intro struck a chord, I promise Thomas also some butter
on his bread if this ever will become official :-)
| | | (8) Posted by Dmitri Turevski [Thursday, Oct 24, 2019 13:25] |
According to the minutes of the Rhodes meeting the proposal was accepted by the assembly of the PCCC delegates:
QUOTE
separate votes; part a): 21 in favour, 1 against, 2 abstentions; part b) 20 in favour, 6 abstentions
www.wfcc.ch/wp-content/uploads/2013/05/Minutes2007-Rhodes1.pdf
Can't really get more official than that.
| | | (9) Posted by Mihail Croitor [Thursday, Oct 24, 2019 15:35] |
No big problem to introduce another chess problem description format, if will exists good transpiler, i think. Portable Problem Notation can be based on PGN, just with some additional fields, such as [Author ""], [Source ""], [Stipulation ""], [Distinction ""]
What is good on xml representation: XML schema definition existence. Olive format can be specified by JSON schema definition.
| | | (10) Posted by [Friday, Oct 25, 2019 07:30]; edited by [19-10-25] |
> According to the minutes of the Rhodes meeting the proposal was accepted by the assembly of the PCCC delegates:
Sort of. According to the minutes the proposal was accepted as a provisional standard format for exchange of chess composition data.
Note: provisional. That usually means that it is on trial, and expected to be a final standard. But it is still on trial: if the experiences are negative, it can be withdrawn.
It was also noted that it would be used for current competitors to submit entries, and that it would be up to software providers to provide viewers, converts and other software.
That was in 2007. What are the experiences today? Is there such software? Are entries in competition sent by this format?
My own gut feeling is that if everything was working as expected, the provisional standard (2007) would have become a full standard.
But I haven't found any indication of that -- though I may very well have missed something.
Back in 2007 Thomas did note that the initial use of the proposed format was not the one I was and am primarily interested in: that of collecting information from old sources, but a more limited one. (That's why I complained about the very strict notion of how problem author names would be specified: it makes good sense for the proposed use, but it doesn't work for historical problems, where a signature such as "T. P. C." cannot usually be positively identified as a personal signature, and for that reason may have no part that can be called a familyname.)
This may also need to be taken into consideration.
| | | (11) Posted by Dmitri Turevski [Friday, Oct 25, 2019 08:51] |
The greatest thing about the problem-xml, in my opinion, is that, despite obvious drawbacks, it is very well-thought-out. I'm considering adopting the source/award/reprint semantics for the yacpdb right now.
I agree that choices as when to enforce strictness could have been addressed differently, but I'm not sure I get the "familyname" criticism: the "author" element is completely optional within the "release" element and there is the "text" element where you can put any additional release information including acronyms and signatures in free format.
That's also a common problem with the yacpdb, by the way - people tend to put information where it does not belong simply because it would look nicer above the diagram, for example, effectively screwing up the search facilities.
| | | (12) Posted by [Friday, Oct 25, 2019 16:09]; edited by [19-10-25] |
> ... but I'm not sure I get the "familyname" criticism:
The author of problem X is "T. P. C." That's a signature, not a name. And none of the parts T or P or C correspond to a name.
Yet, it will almost certainly end up as <familyname>T. P. C.</familyname> just because there is no reasonable alternative. And that leads
to all kind of later problems, as you note. (In current YACPD it seems to end up as 'C., T. P.' because that format is being enforced. It's
a problem of the same kind: the data model does not provide for reality.)
But it is not a likely problem for modern problems, say, in the current FIDE album. It is always going to be a problem
at the other end of the timeline, where standards and conventions are still being worked out.
But I fear I'm riding my particular hobby horse again.
| | | (13) Posted by Dmitri Turevski [Friday, Oct 25, 2019 17:03] |
QUOTE
The author of problem X is "T. P. C."
The author of the problem X is unknown. Both problem-xml and yacpdb allow to indicate exactly this fact by omitting the authorship elements. Neither format enforces to use family and given name fields for other data.
QUOTE
none of the parts T or P or C correspond to a name
This, however, suggest that the real author name is known to you? Then that's what should go to the authorship fields (despite the fact that it was published without it).
QUOTE
because there is no reasonable alternative
But there is! There's problem.release.text in problem-xml and the comments section in the yacpdb. The use of the signature is valuable piece of information and these fields were specifically designed for this kind of data.
So what is the actual problem with the data model?
This topic could be my hobby horse as well.
| | | (14) Posted by [Saturday, Oct 26, 2019 10:46]; edited by [19-10-26] |
>The author of the problem X is unknown. Both problem-xml and yacpdb allow to indicate exactly this fact by omitting the authorship elements. Neither format enforces to use family and given name fields for other data.
But the author isn't unknown. The problem was printed as "By T. P. C., of New York". That's a clear statement of authorship, even if it may be impossible to interpret confidently. The fact that you may not be able to interpret it may affect how *you* enter this problem. Me, I transcribe problems: whatever is present on the printed page (so to speak) goes in. Even if I can't make sense of it -- I always hope that someone else knows more than I do, or that I, in the same column, three months later, come across a message from the editor that says 'the author of problem X was printed as T. P. C.; we can now reveal that our contributor ...<full name here>... used that signature in another publication from which we reprinted it" ... or, "it was a misprint for ...something else...".
So to me it makes better sense to have the options: a) this is a well-formed personal name, b) this is what was printed, but I can't say there's a personal name anywhere in there. problem-xml adds the option of also providing a VCard. Nice, I have no problems with that.
>This, however, suggest that the real author name is known to you? Then that's what should go to the authorship fields (despite the fact that it was published without it).
Very well, you have a different approach than I do. I transcribe: if a problem is printed as by 'S. Lloyd' that's the authorship information, even though it most likely is a misprint. You, seemingly, would correct it on the fly. Yet there is at least one person out there named Lloyd who composed problems: that is, it may not be the Lloyd that may be wrong, it may be the S. And if I run into one problem printed as by "T. Kling" ... that's what I enter. (This one is fairly common: I suspect J. Kling's longhand may have had a J that was pretty close to English normal longhand T , and so liable to be misread.)
Would you correct "C. Stanley" to "C. H. Stanley"? if you did, you'd may be falsifying the author. C. H. Stanley is not the same person as C. Stanley, who lived in Bristol, and also published some odd problems.
T.P.C. is an abbreviation for "The Problem Club", a seemingly loose grouping of U.S. problemists (mainly New York, I think) who published problems they worked on together under that signature. Loyd was one of them, and some problems originally published as by "T. P. C." have appeared in American Chess-Nuts under Loyd's name. Other appear under the name of other authors. That is, T. P. C. cannot necessarily be converted to a specific name.
Here's one of those problems. Saturday Press had another just one or two months later.
Saturday Press, October 20, 1860
By T. P. C., of New York
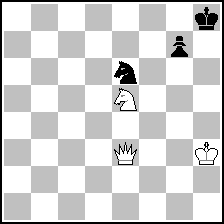 (= 3+3 ) (= 3+3 )
Mate in five
7k/6p1/4s3/4S3/8/4Q2K/8/8
[later correction in Saturday Press: there should have been no Knight on e6. This correction adds to the piquancy of this problem :-) ]
Same thing with any signature or pseudonym. I come across "W. G." in London Illustrated News in the late 1840s. I may suspect it's Grimshaw, but I can't decide that it is. After another few months, when W. G. gradually has become Mr. W. Grimshaw, then W. Grimshaw, and finally just Grimshaw (suggesting a well-known and respected contributor) I may have enough material to say 'W.G.' is probably W. Grimshaw. If one of these problems has been reprinted later by someone who took care about source attribution, I may even say that W. G. is that Walter Grimshaw. I can only hope that when, after that, a problem by just "N. Grimshaw" appears I don't automatically correct it to 'W. Grimshaw'.
I think of a chess problem database as a research tool, where information needs to be collected, gradually, over time, by multiple people, to help make those decisions. You, I suspect, may think of it as a publishing tool, dealing with reasonably well known information. From some point in time, your point of view will be the better one. What I feel is important is that this design choice or use-case model is expressed clearly *as*well*as*enforced* by applications in order keep data rot at bay. Go back to old Chess Player's Chronicle or the early years if Bell's Life in London, and you find problem by problem by 'B. X.' or 'K---e' or 'McG---y' or even 'Omicron', which may be a pseudonym but also could perhaps be a family name. I hesitate to assert 'this is a family name', when I have no positive information that it is. I may even find 'By the editor of Badener Schachzeitung' (though in German) ... and find absolutely no trace of a publication of that name. There's author information, but it can't be attached to a person.
Go to ... say, Manchester City News in the 1920s, and signatures are rare, possibly even extinct, and a data model that assumes that family name are present make considerably more sense.
If I know which model is used I can avoid investing work is something that may become a failure further down the line, when the tricky cases appear.
>But there is! There's problem.release.text in problem-xml and the comments section in the yacpdb. The use of the signature is valuable piece of information and these fields were specifically designed for this kind of data.
I wish it was also easy to do. I have your get data markup convention right. After I've tried two times and failed, I give up. That problem is not going to be entered by me. You may have designed the field for this intended use, but you have not made it accessible to an average user. That however is a different question, concerning user interface; this is a discussion about data markup, and I won't go outside that just now.
But this basically means 'stuff anything you can't state according to the data model into this free text field'. Yet I can say 'this is authorship information'. It doesn't conform to your model, but it still is. And even if it is not according to that model, it can be searched for. And it would even be possible to say 'find all problems for which authorship info' does not contain a family name. All that goes out the window if we just stuff it into a free text field.
>So what is the actual problem with the data model?
It isn't clear what reality it mirrors or is intended to mirror. That of the 1920s, and where information is fully known? if so, I know immediately it's not for me.
At present, about 70 percent of the problems I see don't have anything can be confidently asserted to be a family name. Very frustrating ... but at the same time I know that the Grimshaws and Bodens and Healeys and Andrews are in there under signatures. "B.X." for example ... I suspect he may be someone reasonably well known, but I have not collected enough information to make a connection. The "Judy" and "Stella" pseudonyms belong here, as well, as do mottos from chess tournaments.
If an introduction to the markup format (or the database, in those cases the database is behind a user interface) says 'this is what this markup / this database has been designed to do. If you need to go outside this model, you're going to have problems, and if you persist you may damage normal use' -- then at least there's a chance to avoid such misuse. It would still need active checks to assure the wanted level of data quality, however. (This is where read-only databases may make very good sense ...)
Perhaps it's easier to say it like this: the examples of its use only show examples that work (well, as far as I have found), never examples that don't work, or that need additional walk-arounds to work. The T. P. C. example above might be good for one such example, I think, even if it is only to say 'This won't work at all. Please, don't try to force it'. There are probably more. A problem from the early publication of B.C.A. 1873 tourney (perhaps from the "Suum cuique" set already available here) may be another -- that motto was never connected to a person, although Loyd has been mentioned as a possibility, but, I think, unlikely to be even a probability.
>This topic could be my hobby horse as well.
In that case, we might perhaps be polite to readers who don't think markup minutiae are particularly exciting, and take any continued conversation off-line?
| | | (15) Posted by Dmitri Turevski [Saturday, Oct 26, 2019 14:07] |
Wow, that was quite a historical and personal digression. Your assumption about my own approach are mostly incorrect, unfortunately.
I'll comment on this bit that seems to me to be really relevant to the topic and will be looking forward for meeting you personally, Anders! (so we could have an offline conversation):
QUOTE
And it would even be possible to say 'find all problems for which authorship info' does not contain a family name. All that goes out the window if we just stuff it into a free text field.
Every model, naturally, has its limitations, it would always be possible to come up with unsupported synthetic queries like 'find all problems which were printed in the left column of the two-column page'. The question, however, is how useful would such queries be.
On the other hand free text search for occurencies of "T. P. C." allows an average user to do real historical research:
www.yacpdb.org/#q/Text("%25T.%20P.%20C.%25")/1
| | | (16) Posted by [Sunday, Oct 27, 2019 06:49]; edited by [19-10-27] |
I'm sorry to hear you felt it was a digression. To me, it was the most central objection to the issue that I was able to formulate.
I'll have to address it in some other way, then.
| | | (17) Posted by Joost de Heer [Sunday, Oct 27, 2019 08:08]; edited by Joost de Heer [19-10-27] |
QUOTE
The author of problem X is "T. P. C." That's a signature, not a name.
Hence the author is unknown. The only thing we know of the author is his (or her or their) signature, not his/her/their identity. Furthermore, if there are two compositions with the signature 'T.P.C.' we don't know if it's the same (group of) person(s), therefore cataloguing them under the same signature is potentially wrong.
A similar discussion took place on Discogs (music database) around the artist 'Friends' (as in 'Artist X and friends').
* Should 'Friends' be linked to 'Unknown'?
* Should there be a new artist 'Artist X And Friends'
* If the latter, should there be a new artist 'Artist X And Friends (2)' the next time this shows up, because we don't know whether the same friends are part of that incarnation of 'Friends'?
None of the solutions is satisfactory.
I would've loved to hear the opinion of my father because his field of expertise was cataloguing and categorisation.
| | | (18) Posted by Dmitri Turevski [Monday, Oct 28, 2019 05:57] |
QUOTE
Furthermore, if there are two compositions with the signature 'T.P.C.' we don't know if it's the same (group of) person(s)
Good point. Furthermore, we do not really know if the second signature is an authorship information at all, it could be a jokester's dedication: "To Petty Colleagues (of New York)" :)
| |
No more posts |
MatPlus.Net Forum Internet and Computing PGN pseudo standard |
|
|
|
 ISC 2024
ISC 2024

